AI翻唱小白教程 | RVC变声
Tips:以下网站均可能需要使用魔法进行访问
1.获取模型
打开 模型网站 寻找想要的模型
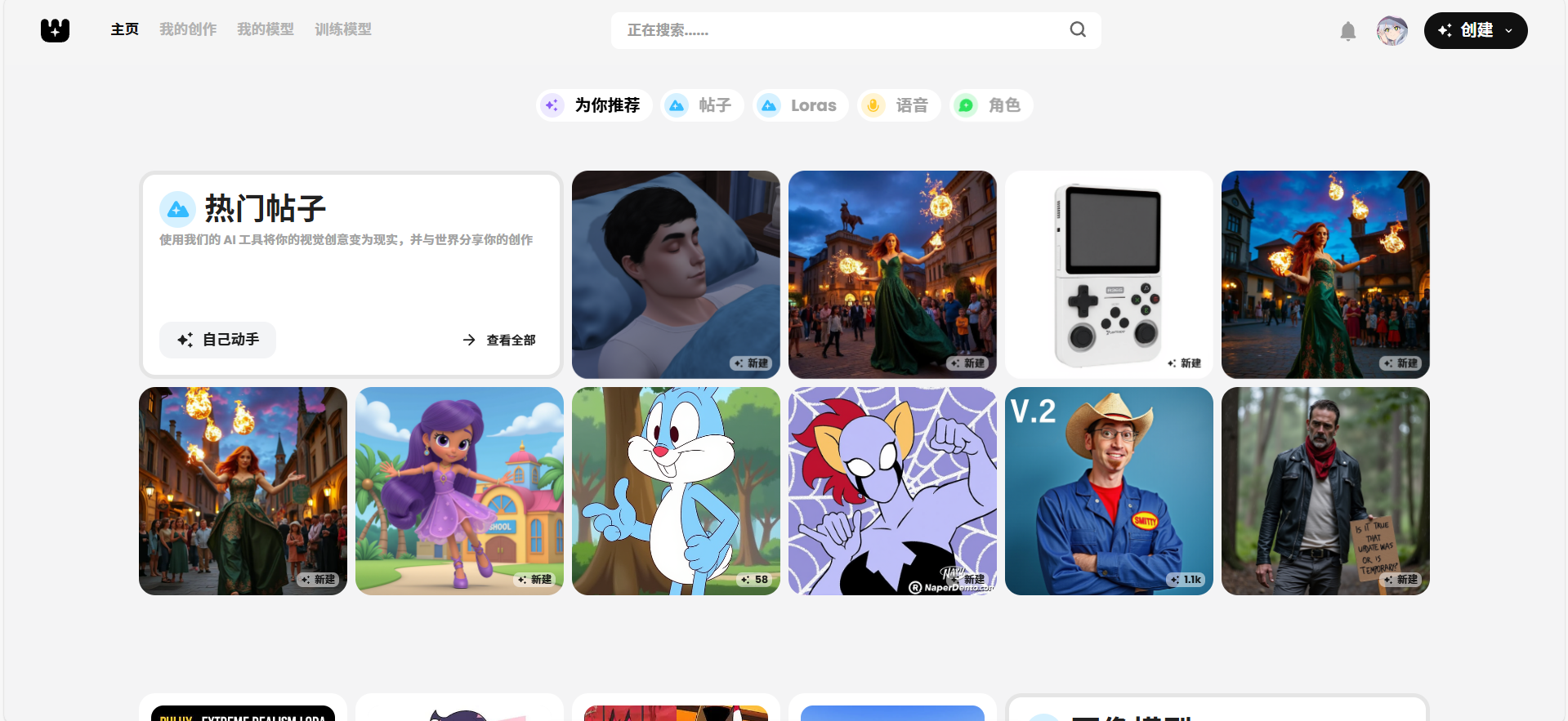
找到心仪的模型后 下载模型
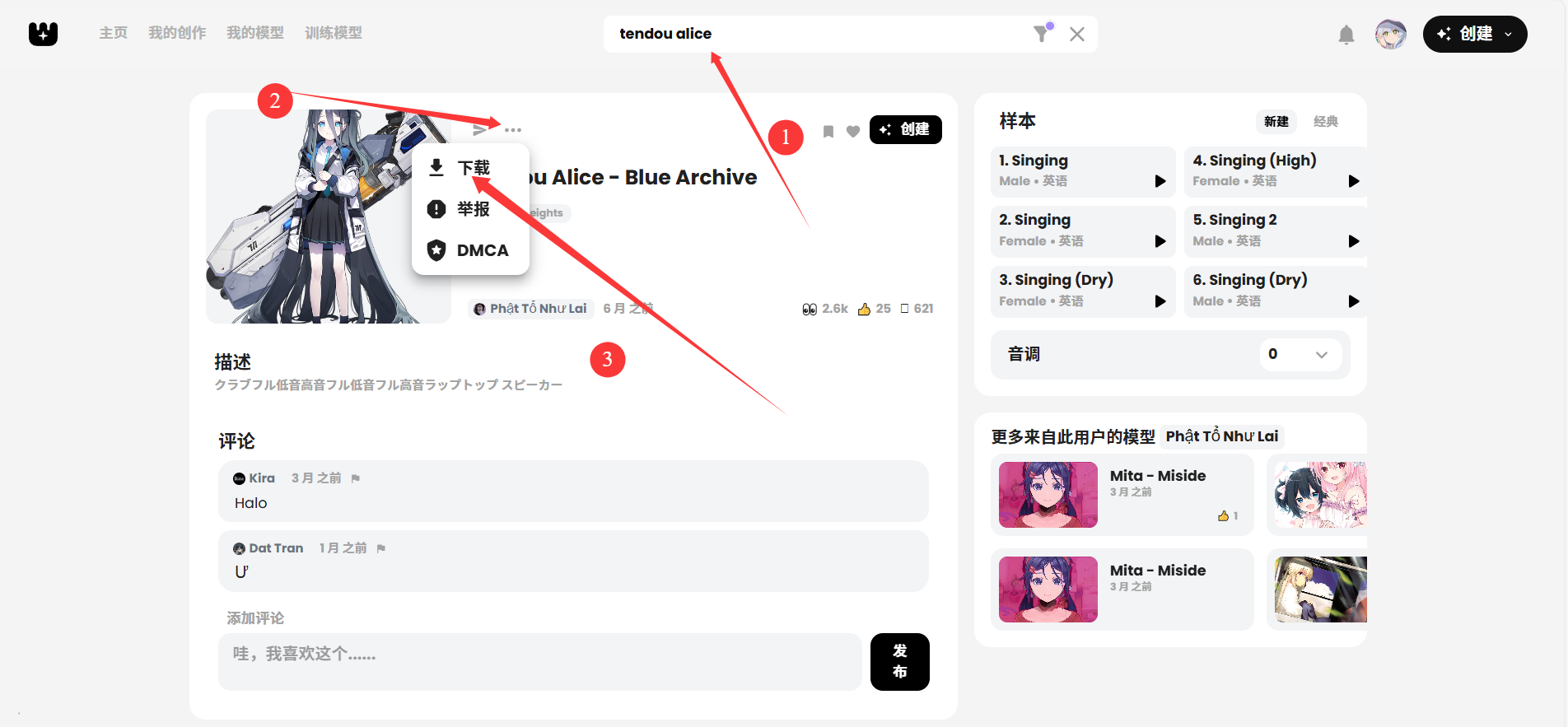
下载下来是一个压缩包,无需解压,先放在一边
2.获取Replay ( 翻唱软件 )
打开 翻唱软件网站 下载软件
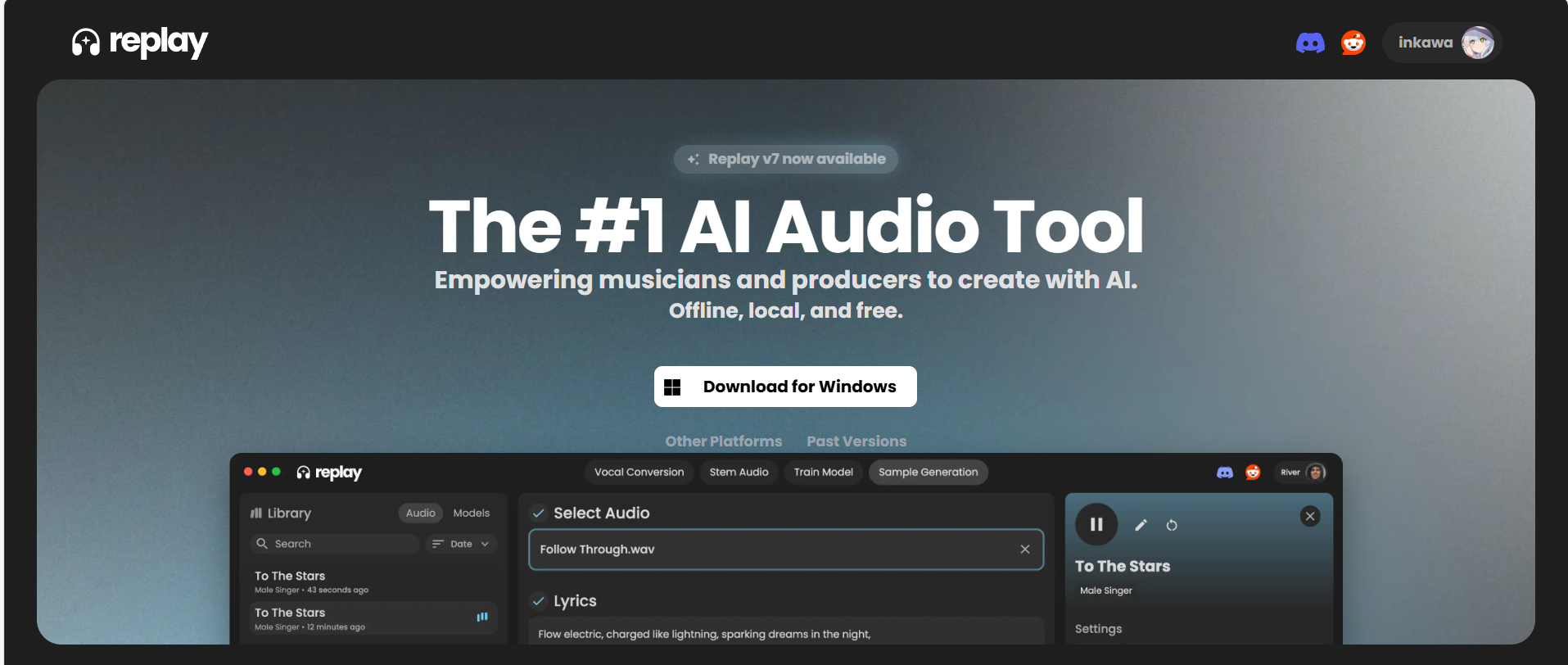
下载安装不再赘述
打开软件后 需要下载一些必备模型 请耐心等待
到这个界面就是可以开始使用了
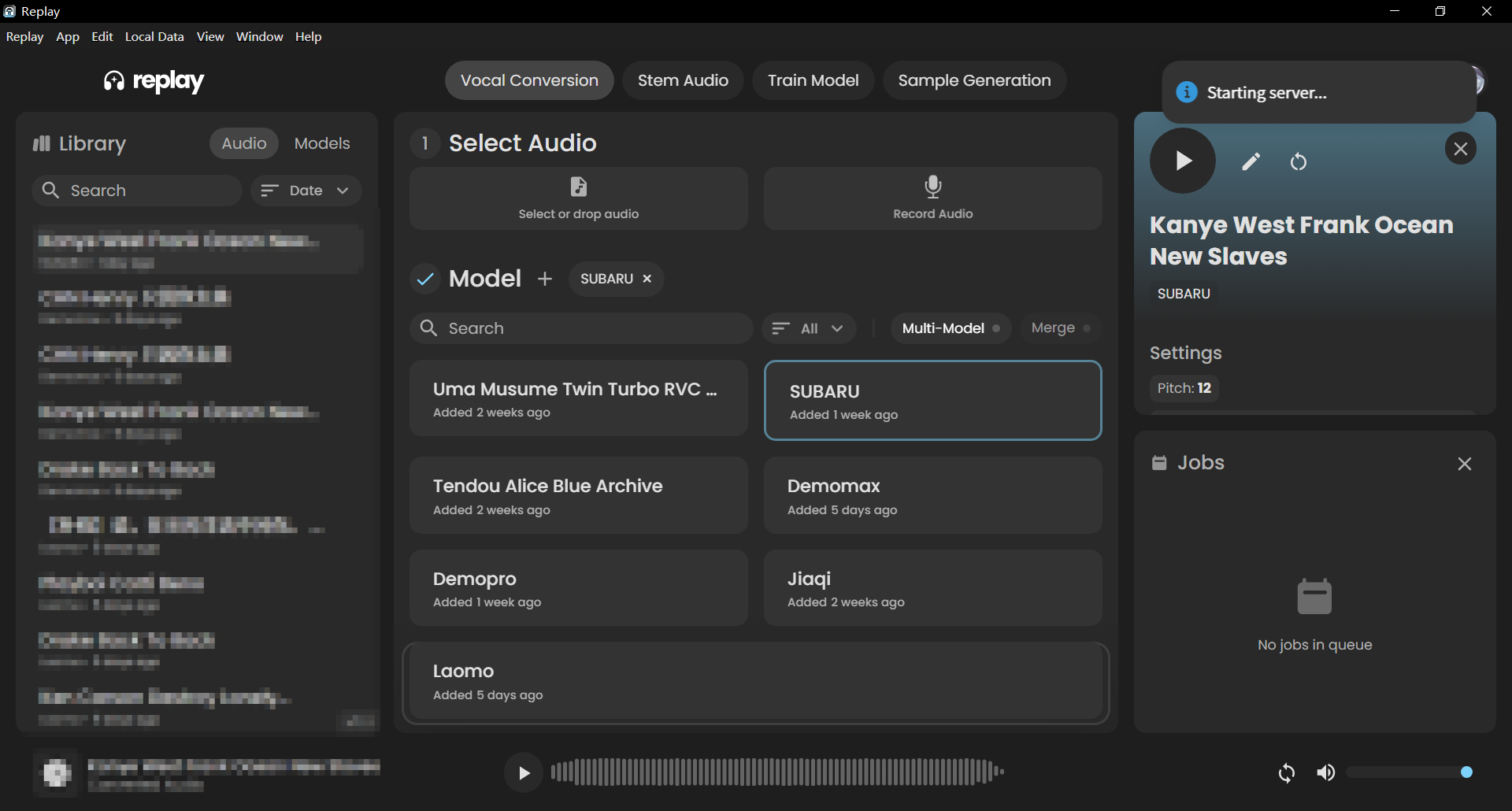
3.导入模型
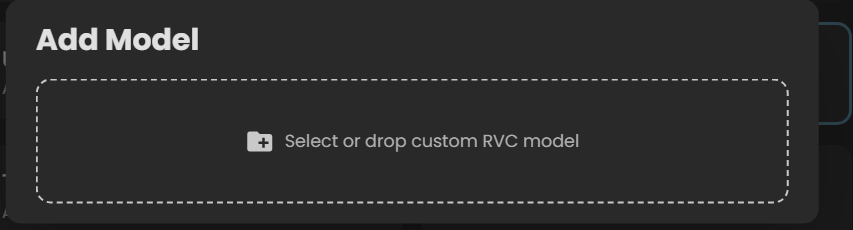
拖入/选择 你刚刚下载的模型压缩包
导入成功右上角会有提示 :)
4.开始翻唱/参数详解
4.1 导入音频
 左边:选择音频文件
左边:选择音频文件
右边:录音
注意:如果你的音频文件带有伴奏,请把stem input开启
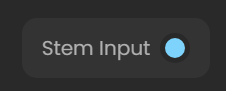 如果是纯人声则关闭
如果是纯人声则关闭
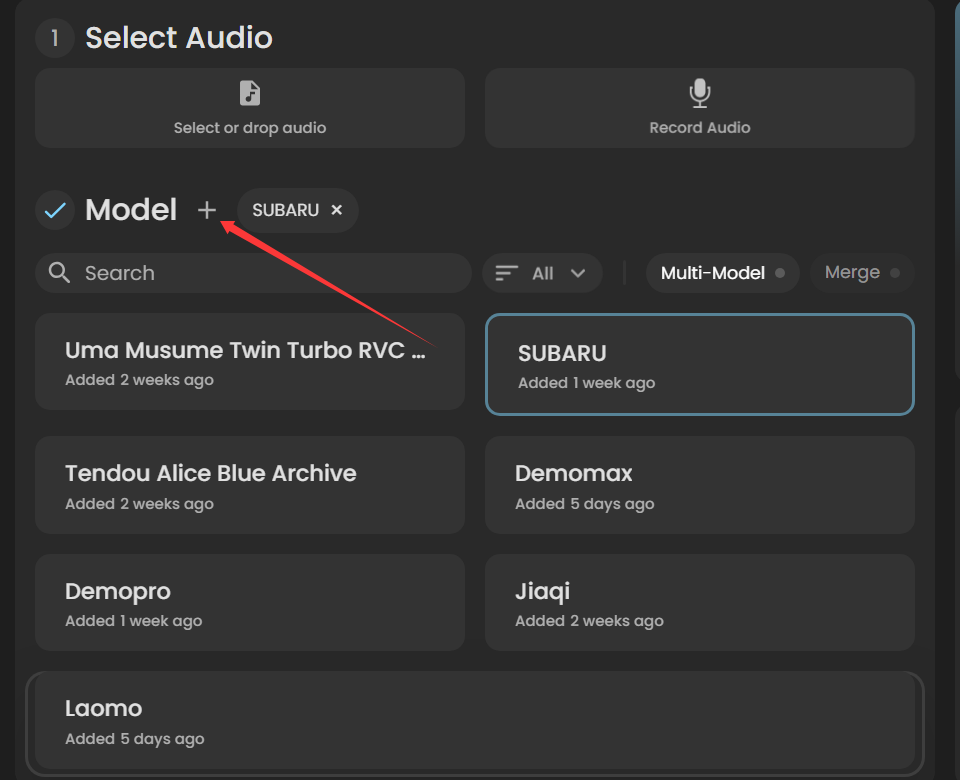
4.2 模型选择
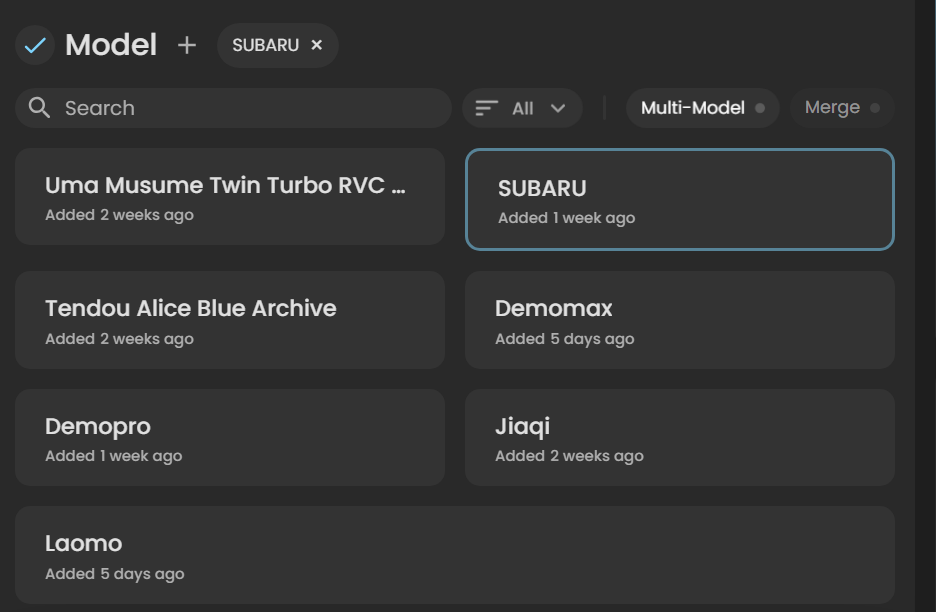
选择要翻唱的模型即可
模型右上角三点可以进行其他操作
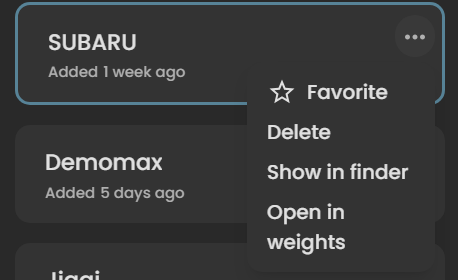
4.3 普通设置
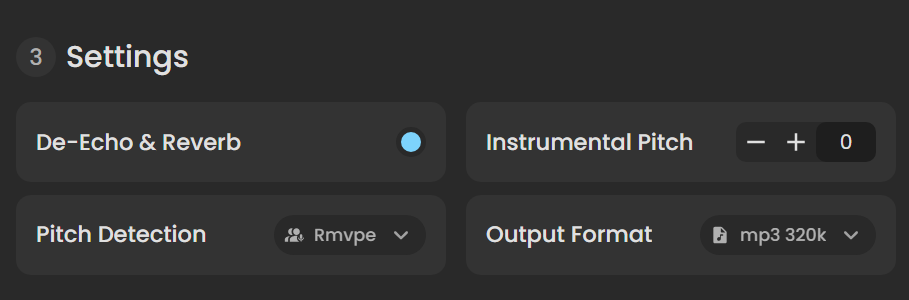
De-Echo and reverb : 去除混响,如果音频是歌曲的话建议开启
Instrumental Pitch:伴奏变调,除非你有需求否则不建议动
更重要的是这个Pitch(在 Convert Audio 按钮的左侧)
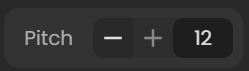
+12为男变女,-12为女变男,0则为原Pitch
Pitch Detection:默认Rmvpe就行
Output Format:输出格式,可自选
4.4 高级设置
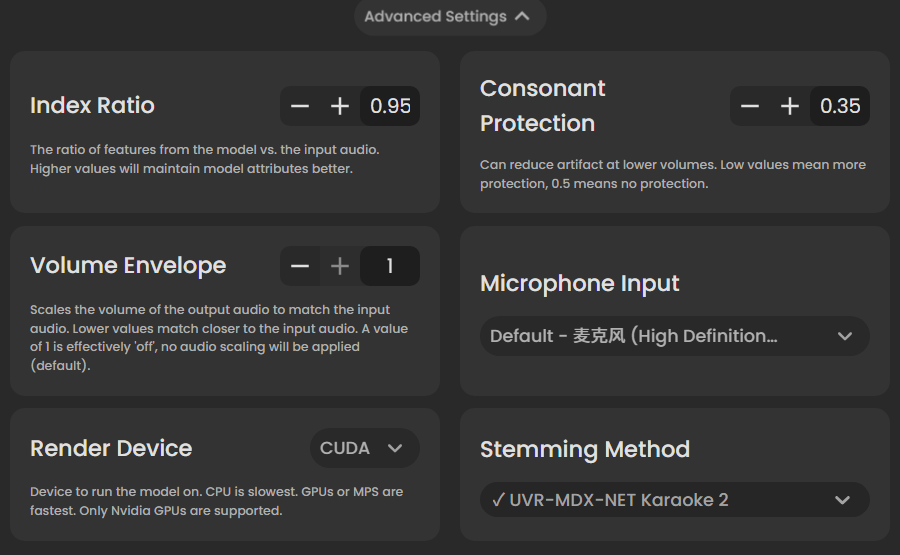
点击箭头展开
Index Ratio:特征索引占比,越低越接近底模,越高越接近模型(如果不懂默认0.75就行)
Consonant Protection 和 Volume Envelope 默认就行
Microphone Input:4.1录音时使用的麦克风设备
————下面两个仅在Stem Input开启时出现,如果你的音频无伴奏或者是录音可跳过————
Render Device:有CUDA就用CUDA,CPU慢而且容易100%
Stemming Method:很重要,分离人声用的
如果你的音频和声较多,而你只想要主要的人声被翻唱,请使用带有Karaoke字样的模型(如Karaoke 2)
如果你想要大部分的人声被翻唱,请使用UVR-MDX-NET Voc FT或UVR-MDX-NET Main
(个人建议,具体使用可以多加尝试,选择效果最好的模型)
4.5 开始翻唱
点击这个诱人的按钮,稍加等待就可以啦 XD

处理完在左侧点击三个点-Download 下载翻唱后的音频

4.6 后处理
如果你觉得有些杂音或者效果不好,可以下载 转换后人声 和 伴奏 ,然后导入到你的宿主软件进行处理


谢谢观看QwQ
